有序表及其在数据处理与存储服务中的应用
在当今数据驱动的时代,高效、可靠的数据处理与存储服务已成为各类信息系统的基石。其中,有序表作为一种基础且强大的数据结构,凭借其独特的性质,在这些服务中扮演着至关重要的角色。本文将探讨有序表的核心概念,并详细阐述其在数据处理与存储服务中的关键应用。
一、 什么是有序表?
有序表是一种线性数据结构,其核心特征在于表中的元素(或记录)按照某个特定的关键字保持有序排列。这个顺序可以是升序或降序。常见的有序表实现包括:
- 有序数组:元素在内存中连续存储,通过二分查找等算法实现高效检索,但插入和删除操作成本较高。
- 平衡二叉搜索树(如AVL树、红黑树):在动态插入和删除的自动维持树的平衡,从而保证查找、插入、删除操作的时间复杂度均为O(log n)。
- 跳表:一种基于并联链表的多层索引结构,同样提供对数级别的操作效率,且实现相对简单。
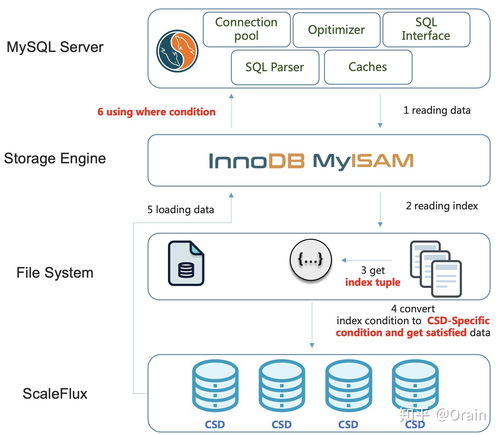
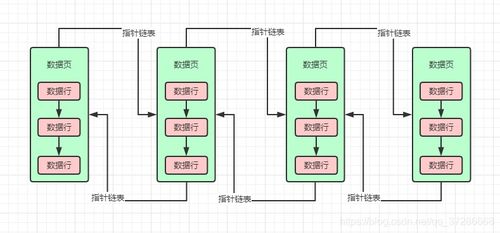
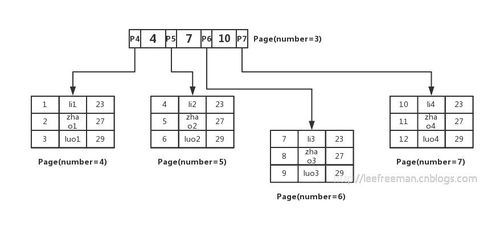
- B树及其变种(如B+树):特别为磁盘等块存储设备设计,能有效减少I/O操作,是数据库索引的标准实现。
有序表的优势在于,它能够将数据的有序性作为一种“预计算”信息,从而支持一系列高效的查询操作。
二、 有序表在数据处理与存储服务中的核心应用
1. 数据库索引
这是最经典、最广泛的应用。数据库系统使用B+树作为其核心索引结构。B+树是一种多路平衡搜索树,所有数据记录都存储在叶子节点并按关键字有序链接,非叶子节点仅存储索引信息。这种结构带来了巨大优势:
- 高效的范围查询:由于叶子节点有序链接,查询“某个区间内”的所有记录(如“2023年1月至3月的订单”)变得极为高效,只需定位到起始点,然后顺序遍历链表即可。
- 优化的磁盘I/O:B+树的节点大小通常设计为与磁盘块大小匹配,一次I/O可以加载大量索引键,极大减少了查询时的磁盘访问次数。
- 稳定的顺序扫描:对叶子链表的顺序遍历,相当于对数据进行了一次全排序扫描,效率很高。
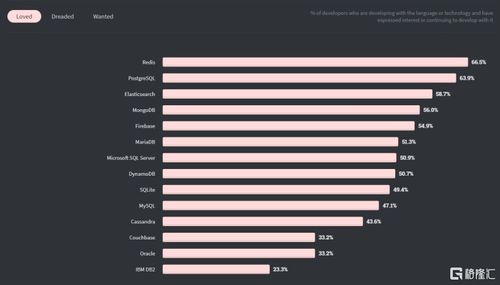
2. 键值存储系统
诸如Redis的Sorted Set(有序集合)便是直接利用跳表(或与哈希表结合)实现的有序结构。用户可以存储成员及其对应的分数(分数即排序关键字),并高效地执行:
- 按分数范围检索成员(ZRANGEBYSCORE)。
- 获取成员的排名(ZRANK)。
- 实时排行榜:这是其典型应用场景,可以毫秒级更新和查询用户在全球或好友中的排名。
3. 搜索引擎的倒排索引
在搜索引擎中,倒排索引记录了每个词项出现在哪些文档中。对于每个词项,其对应的文档ID列表(Posting List)通常被存储为有序表(如增量编码压缩后的有序数组)。有序性使得:
- 布尔查询(如AND、OR) 可以高效执行。例如,查询包含“人工智能”和“深度学习”的文档,系统只需对这两个词项的有序文档ID列表进行高效的合并(交集)操作。
- 结果可以按相关性评分或其他指标(如日期)进行排序和聚合。
4. 时间序列数据库
专门处理带时间戳的数据,如监控指标、金融行情。数据天然按时间戳有序。系统利用有序结构(如LSM树)来存储数据,从而实现:
- 高效的时间范围查询:“查询过去5分钟内CPU使用率”。
- 高吞吐量的写入:通过将数据先写入内存中的有序表(跳表),再批量有序地刷入磁盘,LSM树在保证有序查询的实现了远超B树的写入性能。
5. 大数据分析中的排序与合并
在MapReduce等批处理框架中,Shuffle阶段的中间结果通常需要在Reduce端进行排序后合并。维护一个有序的中间数据结构(如内存中的堆或归并段),是保证数据按Key分组并有序处理的关键步骤,为后续的聚合分析打下基础。
三、 与展望
有序表远不止是一个简单的排序容器。它将“顺序”这一属性固化到数据结构中,从而为上层服务提供了强大的查询原语:精确查找、范围查询、前缀查询、顺序遍历、排名操作等。从数据库的基石B+树,到缓存的Sorted Set,再到搜索引擎和大数据平台,有序表的身影无处不在。
随着数据规模的持续膨胀和新型硬件(如SSD、持久内存)的普及,有序表的实现也在不断演进,例如针对NVMe SSD优化的Bw-tree,以及结合哈希与有序特性的新型索引结构。有序表这一经典概念,必将继续在构建高效、可靠的数据处理与存储服务的道路上发挥不可替代的作用。
如若转载,请注明出处:http://www.ghostplans.com/product/31.html
更新时间:2026-06-18 12:54:36