数据治理体系规划设计方案——数据处理与存储服务专题
数据治理体系规划设计方案
第五部分:数据处理与存储服务
一、 引言与目标
在数字化转型浪潮下,数据已成为组织的核心战略资产。本方案旨在构建一个统一、高效、安全、可扩展的数据处理与存储服务体系,作为整个数据治理体系的坚实技术底座。其核心目标是:
- 标准化处理:规范数据从接入到应用的全流程处理,确保数据质量与一致性。
- 弹性化存储:根据数据价值、访问频率与合规要求,设计分层分域的存储架构,实现成本与性能的最优平衡。
- 服务化供给:将数据处理与存储能力封装成可复用的服务,提升业务部门的数据获取与分析效率。
- 安全可控:贯穿全生命周期的数据安全与隐私保护策略,满足法律法规要求。
二、 核心架构设计
我们的数据处理与存储服务体系采用分层解耦、服务导向的架构,主要包括以下四层:
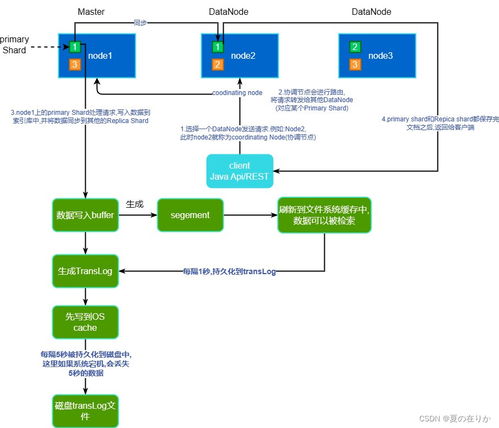
1. 数据源与接入层
- 多源异构接入:支持从业务数据库、日志文件、IoT设备、第三方API等各类数据源的实时与批量数据采集。
- 统一接入规范:制定数据接入标准协议与格式,确保数据入口的规范与质量。
- 关键组件:ETL/ELT工具、消息队列(如Kafka)、数据同步平台。
2. 数据处理与计算层
- 批流一体处理:集成批处理(如Spark, Hive)与流处理(如Flink, Storm)引擎,满足不同时效性要求的数据加工需求。
- 数据处理流水线:通过可视化或代码方式编排数据处理任务,实现数据清洗、转换、聚合、关联的自动化。
- 统一计算资源调度:采用YARN或Kubernetes进行资源管理与隔离,提升集群利用率。
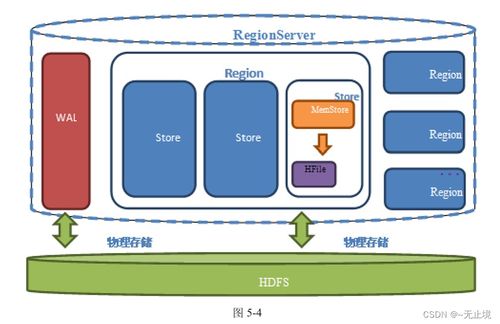
3. 数据存储与管理层(核心)
这是规划的重点,我们设计“三层六域”的存储体系:
- 原始数据层(ODS):
- 存储域:数据湖(如HDFS, S3兼容存储)。
- 定位:存储全量、原始的、未经加工的源数据副本,保留最大粒度信息,用于回溯与探索分析。
- 通用数据层(CDM):
- 明细数据域(DWD):数仓(如Hive, ClickHouse)、MPP数据库。对原始数据进行清洗、标准化、维度退化后形成的业务过程明细数据。
- 聚合数据域(DWS):同一数仓或分析型数据库。基于明细数据,按主题域或业务维度进行轻度汇总的公共汇总层。
- 维度数据域(DIM):关系型数据库或数仓。存储一致性维度表,确保业务口径统一。
- 应用数据层(ADS):
- 个性化数据域:多样化存储(如ES, Redis, MySQL,图数据库)。为满足特定报表、应用接口(API)、数据产品、AI模型训练等需求而构建的个性化数据集合。
- 归档/冷数据域:对象存储或磁带库。用于存储访问频率极低但需长期保留的数据,成本最优。
4. 数据服务与API层
- 统一数据服务网关:提供统一的API访问入口,进行认证、鉴权、限流与监控。
- 多样化数据服务:提供即席查询、固定报表、数据订阅、实时推送、模型评分等多种服务模式。
- 元数据与数据目录服务:提供数据的“地图”与“说明书”,让用户能够快速查找、理解和使用数据。
三、 关键服务流程
- 数据入湖入库流程:定义从数据接入、格式校验、基础清洗到存入数据湖或ODS的标准流程。
- 数据加工与建模流程:基于数据建模成果(维度模型、数据主题域),通过ETL/ELT任务将数据从ODS层逐层加工至CDM层。
- 数据服务化流程:业务方通过数据目录查找数据,申请访问权限,数据团队将CDM层数据或加工后的ADS层数据,通过API、数据文件、数据库账号等方式安全交付。
- 数据归档与销毁流程:根据数据生命周期策略,自动将到期冷数据迁移至归档域,对超过保留期限或无价值的数据执行安全销毁。
四、 技术选型建议
- 大数据基础平台:建议采用云原生大数据平台(如阿里云DataWorks+MaxCompute+DataHub,或AWS EMR+Glue+S3)或基于CDH/TDH的混合云方案。
- 核心存储引擎:
- 数据湖存储:HDFS / 对象存储(S3/OSS/OBS)。
- 数仓与分析引擎:Hive / Spark SQL / ClickHouse / Doris。
- 关系型与事务型:MySQL / PostgreSQL / TiDB。
- 缓存与检索:Redis / Elasticsearch。
- 数据处理与调度:Airflow / DolphinScheduler / 云厂商数据开发工具。
- 数据服务与API管理:API网关(如Kong, Apigee)与自研数据服务中间件。
五、 实施路线图(建议)
- 第一阶段(1-3个月):基础平台搭建与试点
- 完成大数据基础环境部署。
- 建立核心数据源接入通道与原始数据湖。
- 选择1-2个关键业务主题,完成端到端的数据处理与服务化试点。
- 第二阶段(4-9个月):核心体系扩展
- 扩展数据接入范围,覆盖主要业务系统。
- 构建企业级数据仓库(CDM层)的核心主题域模型。
- 建立初步的数据服务目录与API发布能力。
- 第三阶段(10-18个月):服务深化与运营
- 完善分层存储体系,实施数据生命周期管理。
- 深化数据服务能力,支持自助分析与实时数据服务。
- 建立稳定的数据运维体系与持续优化机制。
六、
数据处理与存储服务是数据价值实现的“生产车间”与“仓库”。本规划通过清晰的架构分层、严谨的存储域划分、标准化的处理流程和服务化的交付模式,旨在构建一个灵活、健壮、高效的数据基础设施,为上层的数据分析、智能应用与业务创新提供源源不断的可靠“数据燃料”,最终驱动企业数字化转型的成功。
---
附录:本方案需与《数据标准管理》、《数据质量管控》、《数据安全策略》等专题方案协同实施。
如若转载,请注明出处:http://www.ghostplans.com/product/43.html
更新时间:2026-06-18 00:04:42