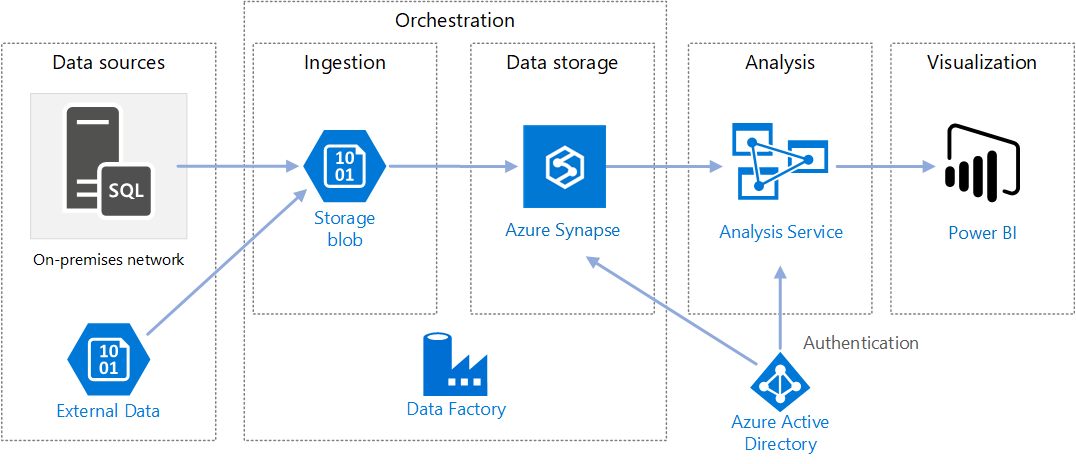
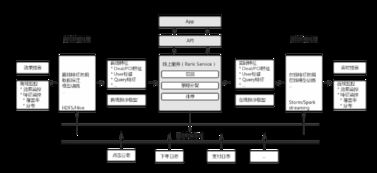
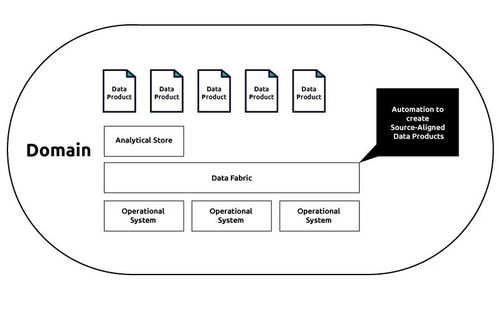
Elasticsearch数据存储流程图解析 数据处理与存储服务全流程
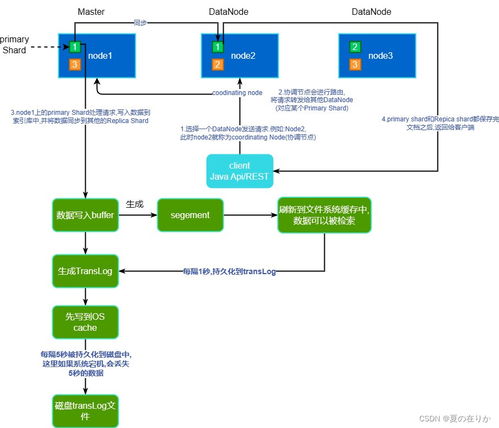
一、数据流入与预处理阶段
1. 数据采集与接收
- 数据通过Logstash、Beats、API接口、Kafka消息队列等多种渠道流入
- 支持JSON、CSV、日志文本等多种数据格式
- 数据接收服务进行初步的格式验证和异常检测
2. 数据解析与转换
- 使用Ingest Pipeline进行实时数据处理
- 字段提取:从原始数据中提取结构化字段
- 数据清洗:去除无效字符、标准化日期格式
- 字段映射:建立字段与数据类型的对应关系
- 数据丰富:添加地理信息、用户标签等附加数据
二、核心存储处理流程
3. 索引创建与映射
- 根据mapping配置自动或手动创建索引
- 定义字段类型:文本、数值、日期、地理坐标等
- 设置分析器:指定分词规则和搜索优化参数
- 配置副本和分片策略:确定数据分布和冗余方案
4. 文档处理流程`
原始文档 → 分词处理 → 倒排索引构建 → Lucene段文件
↓
词项字典建立
↓
位置信息存储
↓
文档ID映射`
5. 分布式存储机制
- 分片(Sharding)策略:
- 主分片:负责数据的写入和存储
- 副本分片:提供数据冗余和高可用性
- 默认配置:5个主分片 + 1个副本分片
- 节点角色分配:
- 数据节点:存储索引数据
- 主节点:集群管理
- 协调节点:请求路由
- 预处理节点:运行Ingest Pipeline
三、存储优化与持久化
6. 写入流程优化
- 缓冲机制:使用内存缓冲区暂存写入请求
- 事务日志(Translog):确保数据的持久性和一致性
- 刷新(Refresh)操作:定期将内存数据转为可搜索状态
- 刷盘(Flush)操作:将数据持久化到磁盘
7. 段文件管理
- 段合并(Merge):将多个小段合并为更大段
- 段优化:删除已标记删除的文档
- 压缩存储:减少磁盘空间占用
四、数据生命周期管理
8. 索引生命周期策略(ILM)`
热阶段(Hot) → 温阶段(Warm) → 冷阶段(Cold) → 删除阶段(Delete)
↓ ↓ ↓ ↓
高频读写 中频访问 低频访问 数据清理
↓ ↓ ↓
SSD存储 HDD存储 归档存储`
9. 快照与恢复
- 定期创建集群快照
- 支持增量备份
- 快速灾难恢复能力
- 跨集群数据迁移
五、监控与维护
10. 存储监控指标
- 磁盘使用率
- 索引大小增长趋势
- 段文件数量和大小
- 缓存命中率
- 写入吞吐量和延迟
11. 存储优化建议
- 根据数据特性选择合适的分片大小
- 合理设置刷新间隔
- 使用合适的压缩算法
- 定期清理过期索引
- 监控热点分片的分布
六、数据处理服务集成
12. 与其他服务协同
- Kibana:数据可视化和仪表板
- Logstash:数据采集和预处理
- Beats:轻量级数据采集器
- 机器学习服务:异常检测和预测分析
13. 数据安全与权限控制
- 基于角色的访问控制(RBAC)
- 字段级安全控制
- 数据传输加密
- 审计日志记录
##
Elasticsearch的数据存储流程是一个高度优化的分布式系统,从数据流入、处理、存储到生命周期管理,每个环节都经过精心设计。理解这个流程有助于:
- 合理规划集群架构
- 优化数据存储性能
- 确保数据安全可靠
- 降低运维成本
- 提升查询效率
通过流程图可以清晰地看到,数据处理和存储服务在Elasticsearch中形成了一个完整闭环,确保海量数据能够高效、稳定、安全地存储和检索。
如若转载,请注明出处:http://www.ghostplans.com/product/54.html
更新时间:2026-06-18 18:29:15