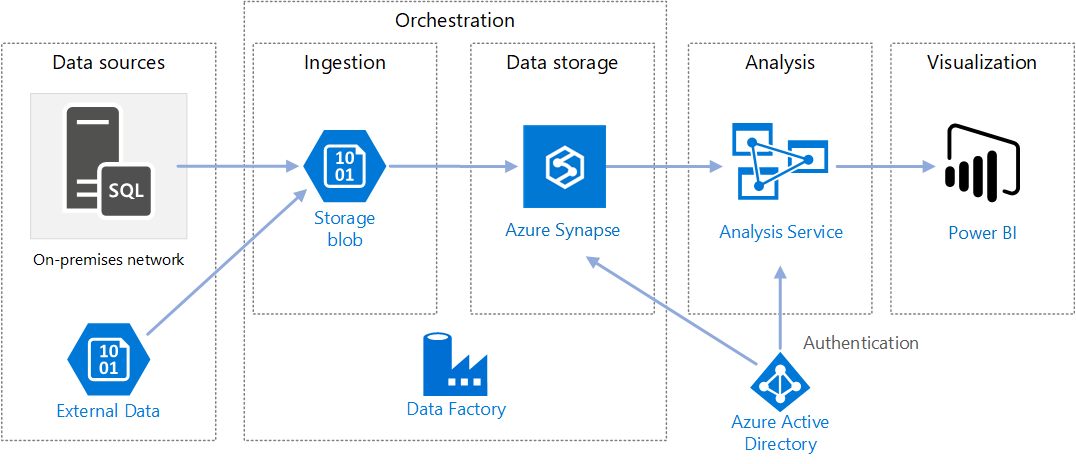
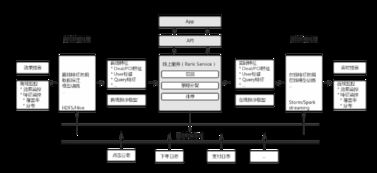
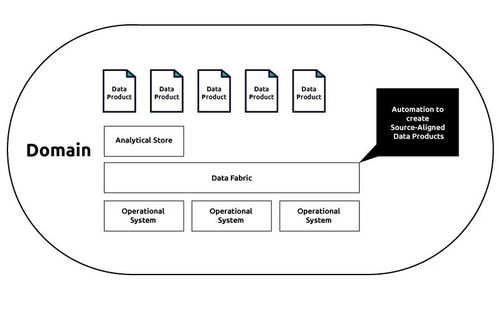
HBase数据存储 高性能分布式数据处理与存储服务解析
在大数据时代,高效、可靠的数据存储与处理成为企业数字化转型的关键。HBase作为一种基于Hadoop的分布式、可扩展的列式数据库,以其高吞吐量、低延迟和强大的水平扩展能力,成为处理海量结构化或半结构化数据的首选解决方案之一。
一、HBase数据存储的核心特性
- 列式存储结构:与传统行式数据库不同,HBase采用列族(Column Family)的存储方式。每个列族包含多个列,数据按列族物理存储,这种设计特别适合稀疏数据集,能有效节省存储空间,并提高查询效率。
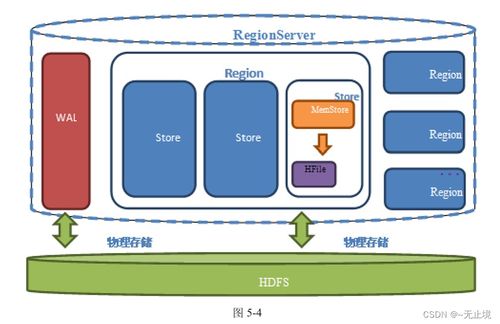
- 分布式架构:HBase构建在HDFS之上,利用Hadoop的分布式文件系统实现数据的可靠存储。数据自动分片(Region)并在集群中分布,支持线性扩展,可通过增加节点轻松应对数据增长。
- 强一致性模型:基于Google BigTable的设计理念,HBase提供强一致性读写,确保客户端总能读取到最新写入的数据,这对于金融、电商等对数据一致性要求高的场景至关重要。
- 高可用性:通过ZooKeeper协调管理,HBase实现了主备RegionServer机制,当主节点故障时能快速切换,保证服务持续可用。
二、HBase数据处理的关键机制
- 数据写入流程:写入操作首先写入预写日志(WAL)确保持久性,然后存入内存存储(MemStore),达到阈值后刷写到磁盘形成HFile。这种机制平衡了写入性能与数据安全。
- 数据读取优化:HBase采用多层索引结构,包括内存中的MemStore和磁盘上的HFile块索引,结合Bloom Filter快速判断数据是否存在,显著减少磁盘I/O。
- 数据压缩与合并:支持多种压缩算法(如GZIP、LZO)减少存储占用;定期执行Minor和Major Compaction,合并小文件、清理过期数据,保持存储效率。
三、HBase作为数据处理和存储服务的应用场景
- 实时查询服务:适用于需要低延迟随机访问的场景,如用户画像查询、实时推荐系统。HBase能在毫秒级响应单条或小范围数据查询。
- 时序数据存储:物联网设备监控、应用日志收集等时序数据,可利用HBase按时间排序的特性高效存储和检索。
- 大数据分析底座:作为Hadoop生态的核心组件,HBase常与MapReduce、Spark等计算框架集成,为离线分析提供稳定数据源。
四、HBase服务化部署与管理
- 集群规划:根据数据规模、读写比例设计Region划分策略,合理配置内存、磁盘和网络资源。
- 监控与调优:通过HBase自带的UI界面或第三方工具监控系统指标(如请求延迟、Region负载),调整参数如阻塞大小、压缩策略以优化性能。
- 数据安全:结合Kerberos认证、访问控制列表(ACL)及加密传输,保障数据在存储和处理过程中的安全性。
五、挑战与未来展望
尽管HBase在众多场景中表现卓越,但也面临一些挑战,如复杂查询支持有限、运维成本较高等。随着云原生技术的发展,HBase正与Kubernetes等平台深度融合,向更弹性、更易管理的云服务形态演进。与NewSQL数据库的竞合推动其持续优化事务处理、SQL接口等能力。
HBase凭借其分布式架构、列式存储和强一致性优势,已成为大数据存储和处理领域的重要基石。企业通过合理设计数据模型、优化集群配置,能够构建出高性能、可扩展的数据服务,支撑起从实时交互到离线分析的全方位数据应用。
如若转载,请注明出处:http://www.ghostplans.com/product/58.html
更新时间:2026-06-18 14:46:56