华为数据入湖标准 数据处理与存储服务的核心架构与实践

在当今数据驱动的时代,企业数据湖已成为整合、管理与分析多源异构数据的关键基础设施。华为作为全球领先的信息与通信技术解决方案提供商,提出了一套系统化的数据入湖标准,其核心在于构建高效、可靠且可扩展的数据处理与存储服务体系。本文将深入解析华为数据入湖标准中数据处理与存储服务的关键要素、架构设计及最佳实践。
一、数据入湖标准概述
华为数据入湖标准旨在解决企业数据孤岛、格式不一、质量参差等挑战,通过统一的数据接入、处理、存储与治理框架,实现数据的资产化、服务化和价值化。该标准强调“原始数据不入湖,入湖必规范”,确保进入数据湖的数据具备明确的元数据、一致的数据格式和可信的数据质量。数据处理与存储服务作为标准的核心支柱,承担着从原始数据到可用数据资产的关键转化任务。
二、数据处理服务:从原始到可用的智能化流水线
数据处理服务在华为数据入湖标准中遵循分层处理原则,通常包括数据接入、数据清洗、数据转换和数据聚合等环节。
- 数据接入层:支持批量、实时和增量等多种接入模式,兼容数据库、日志、文件、IoT设备等多样化数据源。华为提供DataIngest工具集,实现自动化数据抽取与初步格式标准化。
- 数据清洗与转换层:基于预定义的质量规则(如完整性、一致性、准确性校验),自动执行数据去重、缺失值填充、异常值处理等操作。通过ETL/ELT流程将数据转换为目标模型,例如星型或雪花型维度模型,以适应分析需求。华为的DataFusion引擎支持可视化拖拽配置,降低技术门槛。
- 数据聚合与富化层:利用计算框架(如Spark、Flink)进行指标计算、特征工程或数据关联,提升数据的业务价值。华为还集成AI能力,实现智能数据标注、自动分类等高级处理。
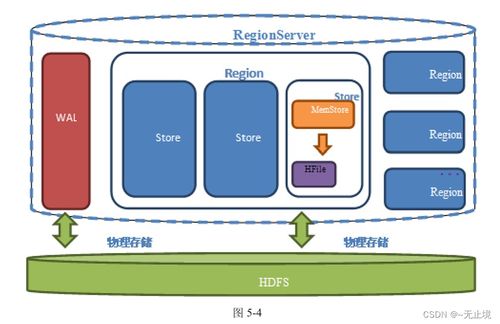
三、数据存储服务:分层存储与统一治理的基石
数据存储服务设计遵循“热温冷”分层存储策略,平衡性能、成本与安全性。
1. 原始存储区:保留未经加工的原始数据,采用低成本对象存储(如OBS),确保数据可追溯性。数据以开放格式(如Parquet、ORC)保存,避免厂商锁定。
2. 标准存储区:存储经过清洗和转换后的标准数据,作为数据湖的核心资产层。华为推荐使用列式存储格式,提升查询效率,并借助数据分区、索引等技术优化访问性能。
3. 服务存储区:面向具体应用场景(如报表、AI训练),提供高性能存储方案(如分布式数据库GaussDB),支持低延迟数据服务。
存储服务与统一元数据管理深度集成,实现数据血缘、权限控制和生命周期自动化管理。
四、关键技术支撑与最佳实践
华为数据入湖标准的落地依赖于一系列自研与开源技术:
- 计算引擎:华为云DataArts Studio提供全流程数据开发能力,结合MRS(MapReduce服务)处理海量数据。
- 存储平台:OBS(对象存储服务)作为湖存储底座,GaussDB用于高性能场景,形成弹性伸缩的存储体系。
- 数据治理:通过DataArts Governance实现数据目录、质量监控与安全策略的统一管控。
实践中,华为建议企业分阶段实施入湖标准:首先定义数据分类与规范,其次搭建基础处理存储平台,再逐步迁移关键数据,并持续迭代治理规则。例如,某金融客户采用该标准后,将数据整合时间从数天缩短至小时级,数据分析效率提升60%。
五、与展望
华为数据入湖标准通过系统化的数据处理与存储服务,帮助企业构建敏捷、智能的数据底座。随着云原生、AI融合及实时化需求的增长,该标准将持续演进,强化实时处理、自动化治理及跨云协同能力,助力企业在数字化浪潮中挖掘数据深层价值。
如若转载,请注明出处:http://www.ghostplans.com/product/37.html
更新时间:2026-06-18 18:32:36