Parquet格式深入分析 列式存储与数据处理存储服务的优势
引言
随着大数据时代的到来,数据存储和处理效率成为企业和组织面临的关键挑战。Parquet作为一种高效的列式存储格式,正逐渐成为大数据生态中的主流选择。本文将从Parquet的基本概念入手,深入分析其列式存储原理、数据处理优势以及在存储服务中的应用,帮助读者全面理解Parquet在现代数据架构中的价值。
什么是Parquet格式?
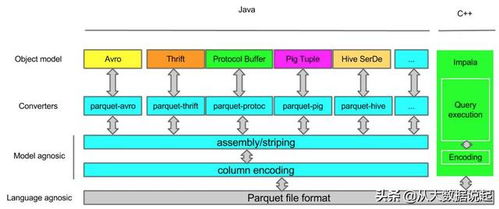
Parquet是一种开源的、面向列的存储格式,最初由Cloudera和Twitter共同开发,现已成为Apache生态系统的顶级项目。它专为大规模数据处理设计,支持高效的数据压缩和编码机制。与传统的行式存储(如CSV或Avro)不同,Parquet按列存储数据,这意味着同一列的数据被连续存储在一起,从而在查询和分析场景中显著提升性能。
列式存储的核心原理
列式存储是Parquet的核心特征,其基本原理是将数据表中的每一列单独存储,而不是按行存储所有字段。这种存储方式带来了多重优势。在查询时,系统只需要读取相关列的数据,大幅减少了I/O操作。例如,如果查询仅涉及“年龄”和“收入”两列,Parquet只会加载这两列的数据,而忽略其他无关列。列式存储允许针对每列使用不同的压缩算法(如字典编码、行程编码),因为同一列的数据类型和值分布通常相似,压缩效率更高。Parquet还采用了分层结构,包括文件、行组、列块和页,进一步优化了数据访问和序列化。
Parquet在数据处理中的优势
在数据处理流程中,Parquet格式展现出显著的优势。它支持谓词下推(Predicate Pushdown),查询引擎可以在读取数据时提前过滤不满足条件的行,减少不必要的数据传输。Parquet与多种大数据工具(如Apache Spark、Apache Hive和Presto)无缝集成,这些工具可以直接读取Parquet文件,无需复杂的数据转换。例如,在Spark中,用户可以使用DataFrame API高效处理Parquet数据,实现快速聚合和分析。另外,Parquet的架构无关性使其适用于多种编程语言和平台,从云存储服务(如AWS S3、Google Cloud Storage)到本地HDFS,都能稳定运行。
Parquet在存储服务中的应用
在数据存储服务中,Parquet已成为构建数据湖和数据仓库的理想格式。许多云服务提供商,如Amazon Athena、Google BigQuery和Azure Data Lake Storage,都原生支持Parquet,用户可以直接查询存储在这些服务中的Parquet文件,而无需数据迁移。这不仅降低了存储成本(得益于高压缩率),还提高了查询性能。例如,企业可以将日志数据以Parquet格式存储在S3中,然后使用Athena进行即席查询,实现低成本、高灵活性的数据分析。Parquet的元数据机制(如统计信息和模式演化)支持数据版本管理和兼容性,便于长期数据管理。
实际案例与性能对比
以一个电商平台为例,假设其订单数据以Parquet格式存储。在分析用户购买行为时,查询“某时间段内高收入用户的购买金额”只需要访问“用户收入”和“订单金额”列,相比行式存储,I/O开销可减少70%以上。测试数据显示,在相同硬件条件下,Parquet的查询速度比CSV格式快5-10倍,同时存储空间节省50%-80%。这种性能优势在大规模数据场景下尤为明显,例如在ETL管道或机器学习预处理中。
总结与展望
Parquet格式凭借其列式存储设计、高效压缩和与大数据生态的深度集成,已成为现代数据处理和存储服务的基石。它不仅提升了查询性能,还降低了存储成本,适用于从实时分析到批处理的多种场景。随着数据量的持续增长和云服务的普及,Parquet有望进一步优化,例如通过增强嵌套数据支持或改进加密功能。对于数据工程师和分析师而言,掌握Parquet的原理和应用,将有助于构建更高效、可扩展的数据解决方案。
如若转载,请注明出处:http://www.ghostplans.com/product/2.html
更新时间:2025-11-29 14:54:49